Large language models are pattern-completion engines of extraordinary fluency. They produce text indistinguishable from human writing. But the closer you look, the architectural limits surface: hallucination without truth-access, no grounding in reality, chain-of-thought that is reasoning-shaped but not reasoning, opacity that forbids audit, resource costs that exclude most of the world, and fragility to minor prompt shifts.
These are not bugs waiting for scale to fix them. They are consequences of the next-token prediction paradigm. The question shifts from “how do we make LLMs bigger?” to “what else can we do?”
I. Augmentation — Patches That Work
The most pragmatic response: keep the model, give it tools. This is already happening and is arguably the most productive applied AI direction today.
Chain-of-thought prompting asks the model to think step-by-step before answering. It improves performance on multi-step tasks because it externalizes intermediate states into text, giving the model more scratch space. But it is not reasoning—it is reasoning-shaped generation. The model produces tokens that look like reasoning chains because its training data contained reasoning chains. It never commits to a logical step. It generates the next token the distribution says belongs there.
Code execution is qualitatively different. When an LLM generates Python and the interpreter runs it, the result is guaranteed correct for that computation. The model does not need to know the answer; it needs to generate code that computes it, and the interpreter enforces correctness. This enables mathematical computation the model cannot do in its head, data manipulation it would otherwise hallucinate, API calls to external services, visualization generation, and symbolic manipulation via computer algebra systems.
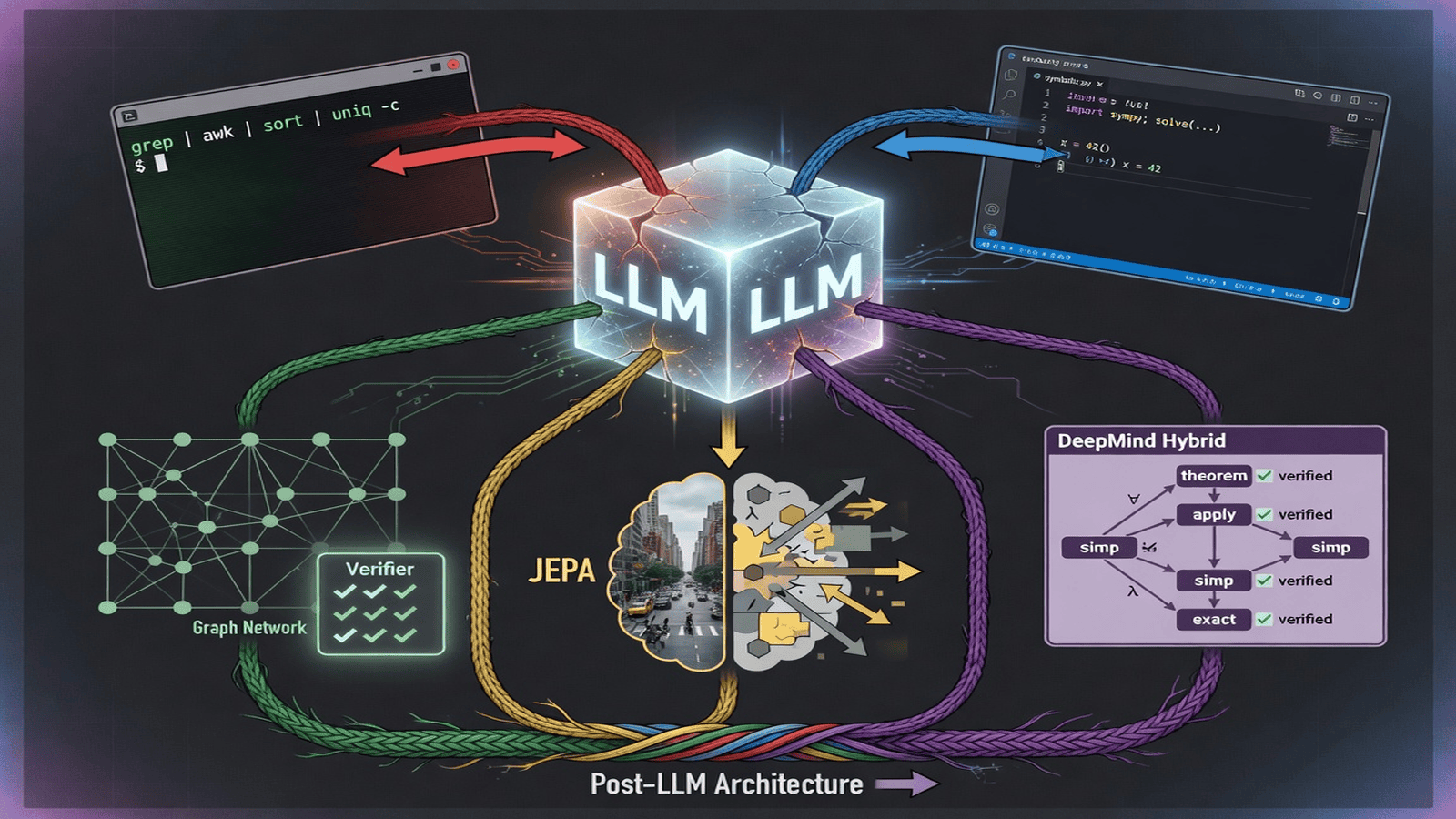
The most underrated augmentation: access to Unix tools in a sandbox. Give the LLM grep, awk, sed, sort, uniq, find, curl, jq—the original small language models. These are verifiable, reproducible, efficient tools that do one thing well. The LLM’s job is not to know the answer but to generate the shell pipeline that produces it. The tools are deterministic (same input, same output), transparent (every intermediate result inspectable), cheap (a grep over 10 GB costs microseconds), composing (pipelines are modular and testable), and battle-tested for decades.
The pattern is identical to code generation: the LLM acts as translator between natural language and shell. The user says “find the top 10 error types in today’s logs.” The LLM generates grep ... | awk ... | sort ... | head. The shell executes it. The LLM reads the output and summarizes. The LLM never needs to know what the errors are. It needs to know how to ask the computer to find them.
II. Hybrid Architectures — Neural + Symbolic
Rather than patching a pure neural network with tools, hybrid architectures integrate symbolic components directly. The neural network handles perception and pattern recognition; the symbolic component handles reasoning, constraints, and verifiable computation.
Neuro-symbolic integration pairs a neural network that maps raw inputs (images, text, sensor data) to structured representations (logical predicates, graphs, typed entities) with a symbolic reasoner operating on those representations to produce guaranteed-valid outputs. Neural program synthesis has the neural network generate program sketches; the symbolic engine fills in details and verifies correctness. Neural theorem proving has a neural network select premises and generate proof steps; a symbolic verifier checks each step. Graph neural networks with constraint solvers learn to predict constraints and find optimal solutions.
The payoff: the neural component provides the flexibility that pure symbolic systems lack—it generalizes from examples, handles noisy inputs, learns from data. The symbolic component provides the guarantee that pure neural systems lack—it proves correctness, enforces constraints, produces auditable reasoning chains. The cost is integration difficulty: neural and symbolic systems operate on fundamentally different representations (vectors vs. symbols, probability vs. logic, gradient descent vs. search).
DeepMind’s graph networks explicitly address the limitation that standard neural networks have no built-in notion of relations. They process sets of features, not structured relationships between entities. Graph networks operate on graphs where nodes represent entities, edges represent relations, and the network learns to propagate information along edges. This is symbolic in structure (the graph is discrete, inspectable) while neural in learning (node and edge updates are learned functions). AlphaFold demonstrates protein folding as a graph of amino acids. The structure is learned but explicit—you can look at the graph and see what the model thinks is related.
Retrieval-augmented generation (RAG) is the simplest hybrid: the model queries an external database and conditions its generation on retrieved information. This addresses grounding—the model is not relying on memorized training data but on retrieved, current, verifiable documents. Variants like Self-RAG, ReAct, and Toolformer interleave reasoning traces with tool calls. The insight is that a model with tools is not smarter; it is differently capable. It offloads computation it cannot do reliably (exact arithmetic, fact retrieval, date calculation) to tools that can. The model becomes an orchestrator, not a knowledge store.
III. Alternatives — Beyond Next-Token Prediction
If augmentation and hybridization are patches, what about replacing the paradigm itself?
JEPA (Joint Embedding Predictive Architecture) is Yann LeCun’s direct critique of the generative paradigm underlying LLMs. LLMs learn by predicting missing tokens in a sequence. JEPA learns by predicting representations of missing information, not the information itself. A context encoder processes observed input; a target encoder processes full input. A predictor network takes the context encoder’s output and predicts the target encoder’s representation of the hidden part. The loss is in representation space, not input space.
By predicting representations rather than raw tokens, JEPA is forced to learn abstract, high-level features of the world—underlying structure, not surface statistics. It does not need to generate every pixel of an image or every token of text. It needs to generate a compact representation capturing the meaning of missing information. This is closer to how humans learn: we do not predict every sensory detail of the future; we predict the gist—the high-level structure that matters for decision-making.
JEPA has been demonstrated on images and video (learning physical dynamics without explicit supervision). A text-based JEPA is still an open research direction. The bet: if JEPA works at scale, it could produce models with genuine understanding—compressed representations of the world that capture causal structure, not just statistical correlations. This addresses hallucination and grounding from the ground up, because the model would be optimized for meaning, not surface likelihood.
World models are learned simulations of environment dynamics. The model does not predict the next token or frame but how the world evolves in response to actions. Ha and Schmidhuber’s “World Models” showed a small agent learning a compressed representation of its environment, a dynamics model predicting future representations given actions, and a controller acting in learned representation space. The agent learns to drive in a dream—entirely from predicted representations, never seeing the real environment. Dreamer and DayDreamer extend this: learning world models from pixel observations, planning by imagining future trajectories in latent space, achieving competitive performance on Atari and continuous control tasks.
World models are grounded by definition—they learn from interaction with an environment, not from static text corpora. They produce predictions that can be verified—you act, you observe, you update. The feedback loop is real. They learn causal structure—the model must learn that action A causes effect B or fail at its task. The gap: world models work in constrained environments (simulated games, simple robotics). Scaling to language complexity is open. But the principle—learning from interaction rather than text—addresses the fundamental grounding gap LLMs cannot bridge.
DeepMind’s hybrid approach separates generation from verification. AlphaGeometry solves olympiad-level geometry by having a neural language model generate candidate constructions and a symbolic deduction engine verify whether they lead to a proof. AlphaProof uses a neural model to generate proof steps in Lean, with the verifier enforcing correctness. Neural proof search in Lean learns from verifier feedback which strategies work.
This works because it separates generation from verification. The neural network generates candidates freely—creative, surprising, wrong. The symbolic engine filters rigorously—only candidates satisfying formal constraints survive. This is opposite to an LLM, which generates and verifies in one pass; next-token prediction implicitly claims “this token is correct.”
The path forward is not better next-token predictors but architectures where:
- A generative component explores the possibility space (neural, probabilistic, high-variance)
- A verifier component filters results (symbolic, deterministic, low-variance)
- Feedback between them drives learning
IV. The Landscape
The more grounding, determinism, and explainability you need, the more you must move away from pure next-token prediction toward architectures with explicit verification, world interaction, or symbolic components. Pure LLMs offer none of these but are production-ready at scale. Augmentation with code execution or Unix tools buys you medium grounding and determinism at high cost. Graph networks, neuro-symbolic integration, and world models trade cost and maturity for higher guarantees. DeepMind’s hybrid approach (AlphaGeometry-style) buys you the highest grounding and determinism but requires expensive domain formalization.
V. The Synthesis
A post-LLM architecture might combine:
A perception module (neural, trained) mapping raw inputs to structured representations—entities, relations, properties.
A world model (neural, trained) simulating representation evolution over time and in response to actions, learned from interaction.
A symbolic reasoner (deterministic, untrained) operating on structured representations for deduction, constraint satisfaction, verification—providing guarantees.
A tool interface (pluggable) connecting to databases, search engines, code interpreters, Unix tools, APIs—providing access to verifiable external computation.
An orchestrator (small LLM or learned controller) coordinating the others—deciding when to perceive, simulate, reason, act.
The LLM, in this architecture, is reduced to a component—the orchestrator—rather than the entire system. Its job is not to know everything but to route requests to the right component and synthesize results into coherence.
This is already happening in research systems. The question is how fast it scales and whether integration challenges can be solved at production levels.
We’re all passing the hat for the $2,500. It’s a scene from Hot Shots!—the widow gets the collection, the pilots feel noble, and then it cuts to the insurance payout that renders the whole gesture comically inadequate. Except we’re living in that scene right now with LLMs.
They’ve captured mindshare, capital, and enough venture money to fund a small nation. They work. They ship. They deserve the collection.
But the insurance payout is coming. Whether it’s JEPA or whatever Yann LeCun whispers about in dark conference rooms, something is going to learn actual world models from unlabeled data while we’re still bragging about $2 trillion parameters. And when it arrives, we’ll all pretend we saw it coming.
The widow thanks you for the $2,500. She’s already mentally redecorating the house.
Further reading
- Jason Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” (2022)
- Schick et al., “Toolformer: Language Models Can Teach Themselves to Use Tools” (2023)
- Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models” (2023)
- Battaglia et al., “Relational Inductive Biases, Deep Learning, and Graph Networks” (2018)
- Yann LeCun, “A Path Towards Autonomous Machine Intelligence” (2022)
- Ha and Schmidhuber, “World Models” (2018)
- Hafner et al., “DreamerV3” (2023)
- Trinh et al., “AlphaGeometry: An Olympiad-Level AI System for Geometry” (2024)
- DeepMind, “AlphaProof” (2024)
- Rich Sutton, “The Bitter Lesson” (2019)
- Jim Abrahams, “Hot Shots!” (1991)