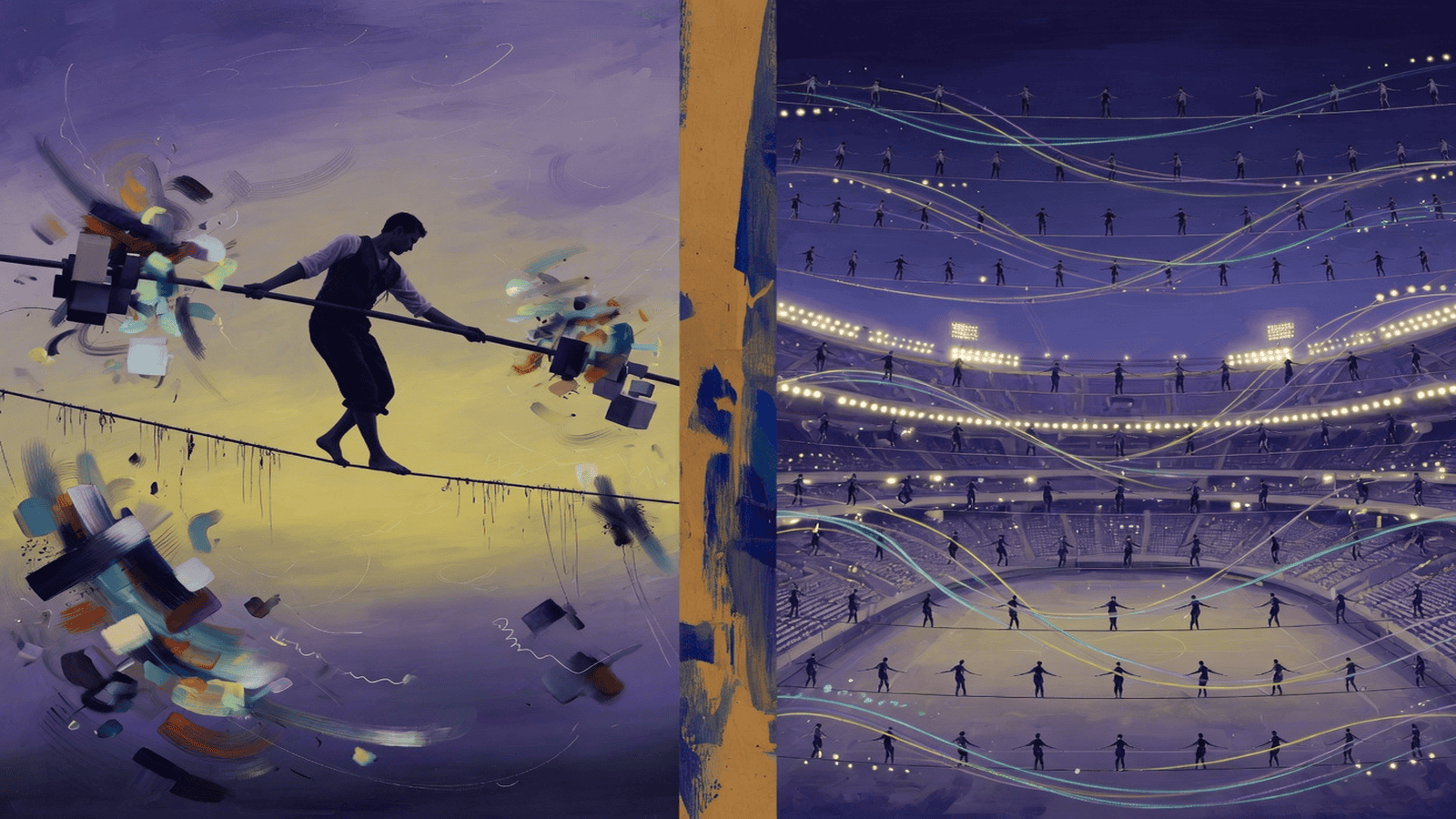Imagine a stadium. Not with a crowd, but with the field itself filled by tightrope walkers, arranged in rows, each on a wire, each holding a long pole. You stand at one end and shout a word. The walkers in the first row feel it—each differently, depending on where they stand—and they wobble, find their balance, and their lamps come on at different brightnesses. That pattern of light falls on the second row. They balance. Their lamps light the third. And so on, through hundreds of rows, until the last row’s lights spell out a single thing: the next word. Then you add that word to what you shouted and do it all again. And again, until you have a sentence, a paragraph, an answer.
That is a large language model. Everything else—the trillion parameters, the data centers, the talk of emergence and understanding—is detail on top of that one picture. Last time I argued that every neural network is the 1958 perceptron stacked and scaled until the ceiling disappeared. This is the same claim from the inside: what the stack actually does, moment to moment, is balance.
I. From One Walker to a Troupe
Begin with a single walker, because that is the perceptron. The pole across their arms carries sliding masses, and their whole task is not to stand still but to adjust as forces arrive. The inputs are the forces—wind, vibration, the shift of weight underfoot. The weights are where the masses sit on the pole, deciding how much each force gets amplified or damped. The bias is the walker’s resting lean before anything arrives. And the threshold is the tipping point: when the accumulated lean crosses it, the lamp trips on. That lamp is not the goal. It is a signal—and in a stacked network, one walker’s lamp is simply another gust of wind for the walker downstream.
One perceptron is one walker on one rope. A deep network is a troupe on stacked ropes, where the lights of the first row become the wind hitting the second. No walker in the middle of the stadium ever feels your shouted word directly; each balances signals it did not originate. This is why depth buys abstraction. The first row learns coarse balance—is there an edge, is there a vowel—and each row above it balances something more distilled, until the walkers on the last rope are no longer responding to raw input at all. They are responding to meaning that has been folded through a hundred prior acts of balance.
II. The Forward Pass
The wobble enters at the bottom and travels up. Each walker reads what the row below is doing, balances against it, and passes their own lamp-state—in a real network a brightness level, not a clean on or off—to the row above. No walker knows what the final answer is supposed to be. None of them can see the end of the stadium. They balance only what reaches them. This upward cascade of local, blind equilibria is the forward pass, and it is almost the entire act of using a trained model. You shout; the wobble climbs; the top row spells a word. The astonishing part is not the mechanism but that a mechanism this simple, repeated at scale, produces language at all.
III. The Backward Pass
But the troupe had to learn to balance, and learning runs the other way. Suppose the final word comes out wrong. The system needs to know who contributed to the error and by how much—and the error signal travels backward through the rows. This is backpropagation, the trick Rumelhart, Hinton, and Williams made practical in 1986. The last walker gets the clearest note: you leaned too far right. They pass a proportional message back—I leaned right because wire three sent me too strong a signal—and that walker passes its share further down, all the way to the first row. Blame is distributed backward; each walker nudges the masses on their own pole by an amount proportional to their fault. How boldly they act on the note is the learning rate: timid, and the troupe learns slowly but stably; aggressive, and it lurches, overcorrects, and sometimes falls the other way. Run this forward-and-backward loop a few billion times over a large fraction of everything humans have written, and the troupe stops falling. It has not memorized the text. It has dissolved the shape of language into the collective balance of the entire stadium—which is why you cannot point to where any fact is stored. It is everywhere and nowhere, smeared across the lean of billions of poles.
IV. The Walkers Learn to Watch Each Other
In a plain stack, each walker sees only the row directly below. They are isolated; there is no looking sideways. Attention is what happens when you let them look. Imagine each walker on a rope able to glance at every other walker on that same rope and decide, for this input, whose lean matters most to them right now. The walker asking is the query: who should I be watching? Every other walker broadcasts a key: here is what I’m doing. And when the answer is you, what gets passed is the value. So a walker no longer just balances the wind from below—it tunes selectively into the walkers most relevant to its situation. Shout the word bank in the context of river, and the river-walker grows loud while the money-walker goes quiet, before the balance even begins. This is the move that the 2017 paper Attention Is All You Need put at the center of everything, and it is why these models hold context so much better than anything before them: the meaning of every word is recomputed in light of every other word in view. The pole’s configuration is no longer fixed per walker. It is recalculated, dynamically, for every single input.
V. The Bet, Not the Decision
Here is the part that unsettles people. The last row of walkers does not pick a word. It assigns a brightness to every word in the language and samples from that spread: shore at twelve percent, water at thirty-one, side at thirty-eight, and so on across the whole vocabulary. The output is not a decision; it is a bet. How wild a bet is the temperature—a name borrowed honestly from physics, from the Boltzmann distribution, where heat is precisely how much a system is willing to wander from its lowest-energy state. Low temperature plays the favorite every time; high temperature takes the long shots, which is why the same prompt can speak twice and never the same way. And this reframes the model’s failures. A hallucination is not a malfunction—it is the troupe producing a confident, well-balanced brightness pattern for an input that fell outside what it trained on. The balance succeeds locally; the answer is wrong globally. It is the telephone game at scale, where a sentence can be perfectly grammatical, perfectly on-theme, and entirely false, because every local constraint was satisfied and no walker was ever in a position to know the world disagreed.
VI. What the Troupe Is, Really
So the levers the field argues about turn out to be small adjustments to this one image. Fine-tuning is nudging the masses on already-trained poles by tiny amounts—which is why it is finicky, why models forget, why a light touch like LoRA works at all. Retrieval is changing what you shout at the first row rather than touching the poles, often the better lever. Even the deepest question—emergence—is just this picture pushed to a scale where no one can say in advance what more walkers, more rows will produce: smoother interpolation, or something genuinely new.
Strip it all back and an LLM is a troupe of billions of tiny balance acts, trained on human language, producing the next word—one at a time—by finding equilibrium between everything you have said and everything it has absorbed. It does not think. It does not know. It balances, at a scale and precision that produces something which, from the outside, looks remarkably like understanding.
It is worth lingering on the pun the metaphor keeps offering. A troupe is the company; a trouper is the performer in it who never misses a cue; and the Super Trouper—the follow-spot ABBA named a song after—is the single blinding beam that lifts one figure out of the dark. The light that matters here is never any one walker’s lamp but the glow the whole stadium throws together, which is precisely where the hard question hides: is the shining a property of the individual light, or only of the sum? That is the emergence question in a stage costume. And the cruelty of the super trouper is that the performer standing inside it sees nothing—the beam that makes them visible to the whole room blinds them to it. Philippe Petit, crossing eight times between the towers on a wire a quarter-inch thick, could not have told you mid-span whether what he did was understanding or merely balance; in the middle of the act, balance is the only truth there is. Neither the walker nor the troupe is positioned to say what the light means. They are the ones standing in it.
The tightrope walker is an older image than any of this. In Nietzsche’s prologue, a funambulist crosses the rope strung above the marketplace—the rope between beast and overman—and is killed not by the abyss beneath him but by a jester who leaps over him from behind, shrieking that he is too slow, that he blocks the way for one better than himself. The autoregressive troupe has no shortage of candidates for that jester—Yann LeCun’s world models loudest among them, calling next-token prediction a doomed off-ramp—and an abyss of its own: the megawatts it burns to stay upright. Which one takes it down, if either does, is the single balance act the troupe cannot perform. It cannot look back to see who is gaining.
Which leaves the one question the song was really asking all along, and the one the field can’t answer either: who is the super trouper—the light that finally, actually shines—and when is it going to show up? Until then the troupe keeps balancing under the beams, scanning the crowd, hoping tonight’s the night.
Further reading
- Vaswani et al., Attention Is All You Need (2017) — the transformer, where walkers learn to watch each other
- Rumelhart, Hinton & Williams, Learning representations by back-propagating errors (1986) — blame traveling backward
- Hu et al., LoRA: Low-Rank Adaptation of Large Language Models (2021) — fine-tuning a limited set of poles
- Bender, Gebru et al., On the Dangers of Stochastic Parrots (2021) — the case that balance is not understanding
- Yann LeCun, A Path Towards Autonomous Machine Intelligence (2022) — the world-model (JEPA) case that next-token prediction is a doomed off-ramp
- Friedrich Nietzsche, Thus Spoke Zarathustra (1883) — the tightrope walker, and the jester who leaps over him
- 3Blue1Brown, But what is a neural network? — the clearest visual intuition for the forward pass
- Super Trouper (ABBA, 1980) — the follow-spot, and the song that made its blinding beam a metaphor
- Man on Wire (2008) — Philippe Petit between the towers, on balance as the only truth in the middle of the act