Les modèles de langage de grande taille sont des moteurs d’achèvement de motifs d’une fluidité extraordinaire. Ils produisent un texte indissociable de l’écriture humaine. Mais plus on observe, plus les limites architecturales émergent : hallucination sans accès à la vérité, aucun ancrage dans la réalité, chaînes de pensée qui ont la forme du raisonnement mais ne sont pas du raisonnement, opacité qui interdit l’audit, coûts de ressources qui excluent la majorité du monde, et fragilité face à des changements mineurs dans l’invite.
Ce ne sont pas des bogues attendant que l’échelle les corrige. Ce sont des conséquences du paradigme de prédiction du prochain jeton. La question se déplace de « comment rendons-nous les LLM plus grands ? » à « que pouvons-nous faire d’autre ? »
I. Augmentation — Des Correctifs qui Fonctionnent
La réponse la plus pragmatique : conserver le modèle, lui donner des outils. Cela se produit déjà et est probablement la direction IA appliquée la plus productive aujourd’hui.
L’enchaînement de pensée demande au modèle de réfléchir étape par étape avant de répondre. Il améliore les performances dans les tâches multi-étapes parce qu’il externalise les états intermédiaires en texte, donnant au modèle plus d’espace de travail. Mais ce n’est pas du raisonnement—c’est une génération en forme de raisonnement. Le modèle produit des jetons qui ressemblent à des chaînes de raisonnement parce que ses données d’entraînement contenaient des chaînes de raisonnement. Il ne s’engage jamais dans une étape logique. Il génère le jeton suivant que la distribution dit y appartenir.
L’exécution de code est qualitativement différente. Quand un LLM génère Python et que l’interpréteur l’exécute, le résultat est garanti correct pour ce calcul. Le modèle n’a pas besoin de connaître la réponse ; il doit générer du code qui la calcule, et l’interpréteur impose la correction. Cela permet le calcul mathématique que le modèle ne peut pas faire de tête, la manipulation de données qu’il hallucinerait autrement, les appels API aux services externes, la génération de visualisations, et la manipulation symbolique via systèmes de calcul formel.
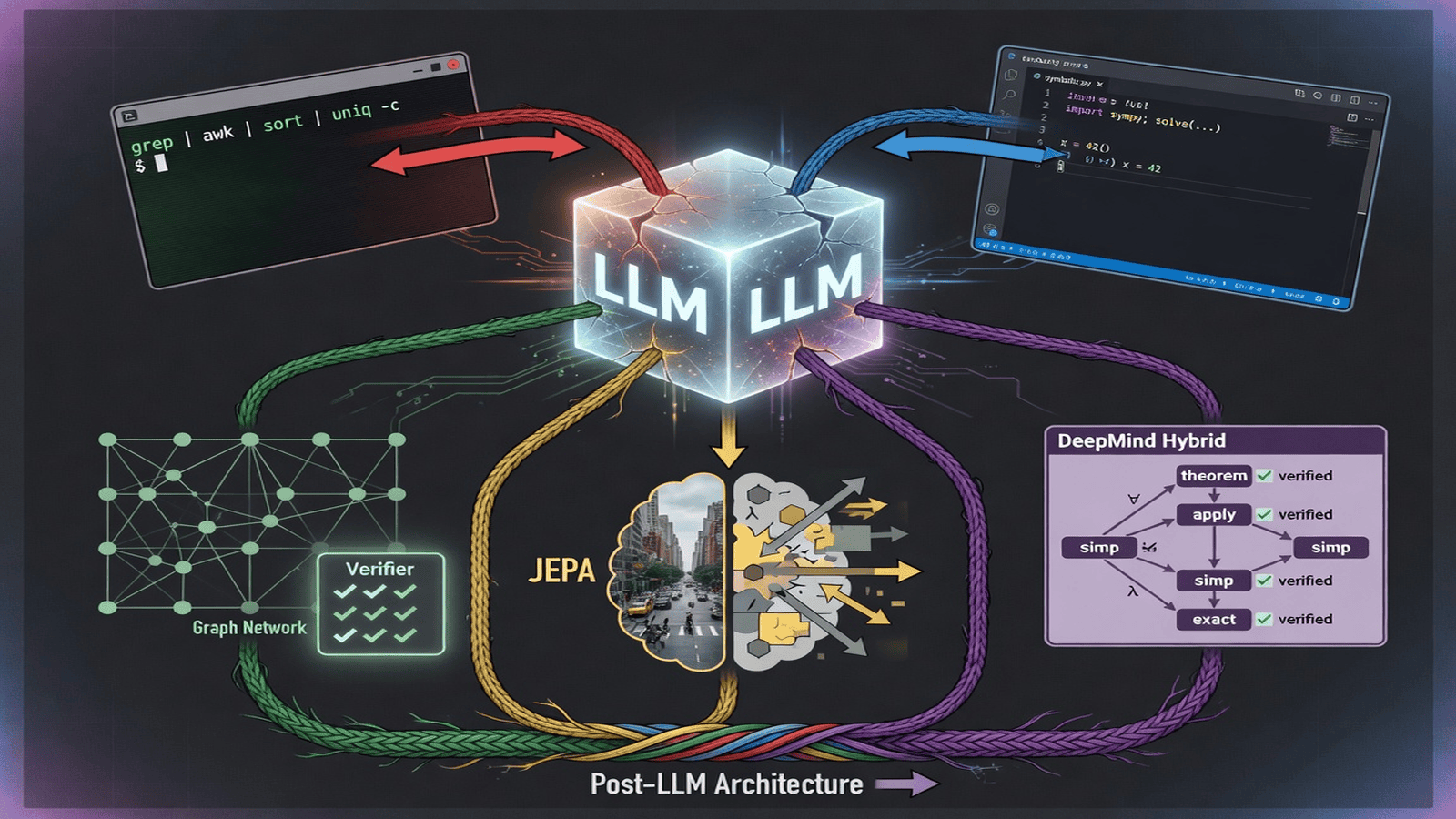
L’augmentation la plus sous-estimée : accès aux outils Unix dans un bac à sable. Donnez au LLM grep, awk, sed, sort, uniq, find, curl, jq—les originaux petits modèles de langage. Ce sont des outils vérifiables, reproductibles, efficaces qui font une chose bien. Le travail du LLM n’est pas de connaître la réponse mais de générer le pipeline shell qui la produit. Les outils sont déterministes (même entrée, même sortie), transparents (chaque résultat intermédiaire inspectable), économiques (un grep sur 10 Go coûte des microsecondes), composables (les pipelines sont modulaires et testables), et testés au combat pendant des décennies.
Le motif est identique à la génération de code : le LLM agit comme traducteur entre le langage naturel et le shell. L’utilisateur dit « trouve les 10 principaux types d’erreurs dans les journaux d’aujourd’hui ». Le LLM génère grep ... | awk ... | sort ... | head. Le shell l’exécute. Le LLM lit la sortie et résume. Le LLM n’a jamais besoin de savoir quelles sont les erreurs. Il doit savoir comment demander à l’ordinateur de les trouver.
II. Architectures Hybrides — Neuronal + Symbolique
Plutôt que de corriger un réseau de neurones pur avec des outils, les architectures hybrides intègrent directement des composants symboliques. Le réseau neuronal traite la perception et la reconnaissance de motifs ; le composant symbolique traite le raisonnement, les contraintes, et le calcul vérifiable.
L’intégration neuro-symbolique associe un réseau neuronal qui mappe les entrées brutes (images, texte, données de capteurs) à des représentations structurées (prédicats logiques, graphes, entités typées) avec un raisonneur symbolique opérant sur ces représentations pour produire des sorties garanties valides. La synthèse neuronal de programme a le réseau neuronal générer des esquisses de programme ; le moteur symbolique remplit les détails et vérifie la correction. La preuve de théorème neuronal a un réseau neuronal sélectionner des prémisses et générer les étapes de preuve ; un vérificateur symbolique vérifie chaque étape. Les réseaux de neurones graphiques avec solveurs de contraintes apprennent à prédire les contraintes et à trouver les solutions optimales.
Le gain : le composant neuronal fournit la flexibilité que les systèmes purement symboliques manquent—il généralise à partir d’exemples, traite les entrées bruyantes, apprend à partir de données. Le composant symbolique fournit la garantie que les systèmes purement neuraux manquent—il prouve la correction, impose les contraintes, produit des chaînes de raisonnement auditables. Le coût est la difficulté d’intégration : les systèmes neuraux et symboliques opèrent sur des représentations fondamentalement différentes (vecteurs vs. symboles, probabilité vs. logique, descente de gradient vs. recherche).
Les réseaux de graphiques de DeepMind abordent explicitement la limitation que les réseaux de neurones standards n’ont pas de notion intégrée de relations. Ils traitent des ensembles de caractéristiques, pas des relations structurées entre entités. Les réseaux de graphiques opèrent sur des graphiques où les nœuds représentent des entités, les arêtes représentent des relations, et le réseau apprend à propager l’information le long des arêtes. C’est symbolique en structure (le graphique est discret, inspectable) tandis que neuronal en apprentissage (les mises à jour de nœud et d’arête sont des fonctions apprises). AlphaFold démontre le repliement des protéines comme un graphique d’acides aminés. La structure est apprise mais explicite—vous pouvez regarder le graphique et voir ce que le modèle pense être lié.
La génération augmentée par récupération (RAG) est le plus simple hybride : le modèle interroge une base de données externe et conditionne sa génération sur les informations récupérées. Cela aborde l’ancrage—le modèle ne s’appuie pas sur des données d’entraînement mémorisées mais sur des documents récupérés, actuels, vérifiables. Les variantes comme Self-RAG, ReAct, et Toolformer entrelacent les traces de raisonnement avec les appels d’outils. L’intuition est qu’un modèle avec outils n’est pas plus intelligent ; il est capable différemment. Il décharge le calcul qu’il ne peut pas faire de manière fiable (arithmétique exacte, récupération de faits, calcul de date) aux outils qui le peuvent. Le modèle devient un orchestrateur, pas un magasin de connaissances.
III. Alternatives — Au-Delà de la Prédiction du Prochain Jeton
Si l’augmentation et l’hybridation sont des correctifs, qu’en est-il du remplacement du paradigme lui-même ?
JEPA (Joint Embedding Predictive Architecture) est la critique directe de Yann LeCun du paradigme génératif sous-jacent aux LLM. Les LLM apprennent en prédisant les jetons manquants dans une séquence. JEPA apprend en prédisant les représentations des informations manquantes, pas l’information elle-même. Un codeur de contexte traite l’entrée observée ; un codeur de cible traite l’entrée complète. Un réseau de prédiction prend la sortie du codeur de contexte et prédit la représentation du codeur de cible de la partie cachée. La perte se fait dans l’espace de représentation, pas dans l’espace d’entrée.
En prédisant des représentations plutôt que des jetons bruts, JEPA est forcée d’apprendre des caractéristiques abstraites et de haut niveau du monde—la structure sous-jacente, pas les statistiques de surface. Elle n’a pas besoin de générer chaque pixel d’une image ou chaque jeton de texte. Elle doit générer une représentation compacte capturant le sens de l’information manquante. C’est plus proche de la façon dont nous apprenons : nous ne prédisons pas chaque détail sensoriel de l’avenir ; nous prédisons l’essence—la structure de haut niveau qui compte pour la prise de décision.
JEPA a été démontrée sur les images et les vidéos (apprentissage de la dynamique physique sans supervision explicite). Un JEPA basé sur le texte est toujours une direction de recherche ouverte. Le pari : si JEPA fonctionne à l’échelle, elle pourrait produire des modèles avec une véritable compréhension—des représentations comprimées du monde qui capturent la structure causale, pas seulement les corrélations statistiques. Cela aborde les hallucinations et l’ancrage à la base, car le modèle serait optimisé pour le sens, pas pour la probabilité de surface.
Les modèles monde sont des simulations apprises de la dynamique de l’environnement. Le modèle ne prédit pas le prochain jeton ou cadre mais comment le monde évolue en réponse aux actions. Ha et Schmidhuber ont montré un petit agent apprenant une représentation comprimée de son environnement, un modèle de dynamique prédisant les représentations futures données les actions, et un contrôleur agissant dans l’espace de représentation apprise. L’agent apprend à conduire dans un rêve—entièrement à partir de représentations prédites, ne voyant jamais l’environnement réel. Dreamer et DayDreamer étendent ceci : apprentissage de modèles monde à partir d’observations de pixels, planification en imaginant les trajectoires futures dans l’espace latent, réalisation de performances compétitives sur les tâches Atari et de contrôle continu.
Les modèles monde sont ancrés par définition—ils apprennent de l’interaction avec un environnement, pas d’un corpus de texte statique. Ils produisent des prédictions qui peuvent être vérifiées—vous agissez, vous observez, vous mettez à jour. La boucle de rétroaction est réelle. Ils apprennent la structure causale—le modèle doit apprendre que l’action A cause l’effet B ou échoue à sa tâche. L’écart : les modèles monde fonctionnent dans des environnements restreints (jeux simulés, robotique simple). L’échelonnement à la complexité du langage est ouvert. Mais le principe—apprendre de l’interaction plutôt que du texte—aborde l’écart fondamental d’ancrage que les LLM ne peuvent pas combler.
L’approche hybride de DeepMind sépare la génération de la vérification. AlphaGeometry résout la géométrie au niveau olympique en faisant qu’un modèle de langage neuronal génère des constructions candidates et un moteur de déduction symbolique vérifie si elles conduisent à une preuve. AlphaProof utilise un modèle neuronal pour générer les étapes de preuve dans Lean, le vérificateur imposant la correction. La recherche de preuve neuronal dans Lean apprend des retours du vérificateur quelles stratégies fonctionnent.
Cela fonctionne parce qu’elle sépare la génération de la vérification. Le réseau neuronal génère des candidats librement—créatifs, surprenants, erronés. Le moteur symbolique filtre rigoureusement—seuls les candidats satisfaisant les contraintes formelles survivent. Ceci est opposé à un LLM, qui génère et vérifie en un seul passage ; la prédiction du prochain jeton affirme implicitement « ce jeton est correct ».
Le chemin en avant n’est pas de meilleurs prédicteurs de prochain jeton mais des architectures où :
- Un composant génératif explore l’espace des possibilités (neuronal, probabiliste, haute variance)
- Un composant vérificateur filtre les résultats (symbolique, déterministe, basse variance)
- Le retour entre eux conduit l’apprentissage
IV. Le Paysage
Plus vous avez besoin d’ancrage, de déterminisme, et d’explicabilité, plus vous devez vous éloigner de la prédiction pure du prochain jeton vers des architectures avec vérification explicite, interaction avec le monde, ou composants symboliques. Les LLM purs n’offrent aucune de ces choses mais sont prêts pour la production à grande échelle. L’augmentation avec exécution de code ou outils Unix vous achète un ancrage moyen et un déterminisme à coût élevé. Les réseaux de graphiques, l’intégration neuro-symbolique, et les modèles monde échangent le coût et la maturité pour des garanties plus élevées. L’approche hybride de DeepMind (style AlphaGeometry) vous achète l’ancrage et le déterminisme les plus élevés mais nécessite une formalisation de domaine coûteuse.
V. La Synthèse
Une architecture post-LLM pourrait combiner :
Un module de perception (neuronal, entraîné) mappant les entrées brutes à des représentations structurées—entités, relations, propriétés.
Un modèle monde (neuronal, entraîné) simulant l’évolution de la représentation dans le temps et en réponse aux actions, appris de l’interaction.
Un raisonneur symbolique (déterministe, non entraîné) opérant sur les représentations structurées pour la déduction, la satisfaction des contraintes, la vérification—fournissant des garanties.
Une interface d’outils (enfichable) se connectant à des bases de données, des moteurs de recherche, des interpréteurs de code, des outils Unix, des APIs—fournissant l’accès au calcul externe vérifiable.
Un orchestrateur (petit LLM ou contrôleur appris) coordonnant les autres—décidant quand percevoir, simuler, raisonner, agir.
Le LLM, dans cette architecture, se réduit à un composant—l’orchestrateur—plutôt que tout le système. Son travail n’est pas de tout savoir mais d’acheminer les demandes vers le bon composant et de synthétiser les résultats en cohérence.
Cela se produit déjà dans les systèmes de recherche. La question est à quelle vitesse cela s’échelonne et si les défis d’intégration peuvent être résolus au niveau de la production.
On passe tous le chapeau pour les 2 500 dollars. C’est une scène de Hot Shots!—la veuve reçoit la collecte, les pilotes se sentent nobles, puis coupe à l’indemnité d’assurance qui rend tout le geste comiquement inadéquat. Sauf que nous vivons dans cette scène en ce moment même avec les LLM.
Ils ont capturé l’attention, le capital, et assez d’argent de capital-risque pour financer une petite nation. Ils fonctionnent. Ils se déploient. Ils méritent la collecte.
Mais l’indemnité d’assurance arrive. Que ce soit JEPA ou ce que Yann LeCun murmure dans les couloirs des salles de conférence, quelque chose va apprendre les vrais modèles du monde à partir de données non étiquetées pendant que nous vantons encore nos mille milliards de paramètres. Et quand cela arrive, nous allons tous prétendre l’avoir vu venir.
La veuve vous remercie pour les 2 500 dollars. Elle redécore déjà mentalement la maison.
Pour aller plus loin
- Jason Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” (2022)
- Schick et al., “Toolformer: Language Models Can Teach Themselves to Use Tools” (2023)
- Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models” (2023)
- Battaglia et al., “Relational Inductive Biases, Deep Learning, and Graph Networks” (2018)
- Yann LeCun, “A Path Towards Autonomous Machine Intelligence” (2022)
- Ha and Schmidhuber, “World Models” (2018)
- Hafner et al., “DreamerV3” (2023)
- Trinh et al., “AlphaGeometry: An Olympiad-Level AI System for Geometry” (2024)
- DeepMind, “AlphaProof” (2024)
- Rich Sutton, “The Bitter Lesson” (2019)
- Jim Abrahams, “Hot Shots!” (1991)