Los modelos de lenguaje de gran escala son motores de completación de patrones de fluidez extraordinaria. Producen texto indistinguible de la escritura humana. Pero mientras más se observan, los límites arquitectónicos afloran: alucinación sin acceso a la verdad, ningún anclaje en la realidad, cadenas de pensamiento que tienen forma de razonamiento pero no son razonamiento, opacidad que impide la auditoría, costos de recursos que excluyen al mundo mayoritario, y fragilidad ante cambios menores en el encabezado de la consulta.
Estos no son errores esperando que la escala los corrija. Son consecuencias del paradigma de predicción del siguiente token. La pregunta se desplaza de “¿cómo hacemos los LLM más grandes?” a “¿qué más podemos hacer?”
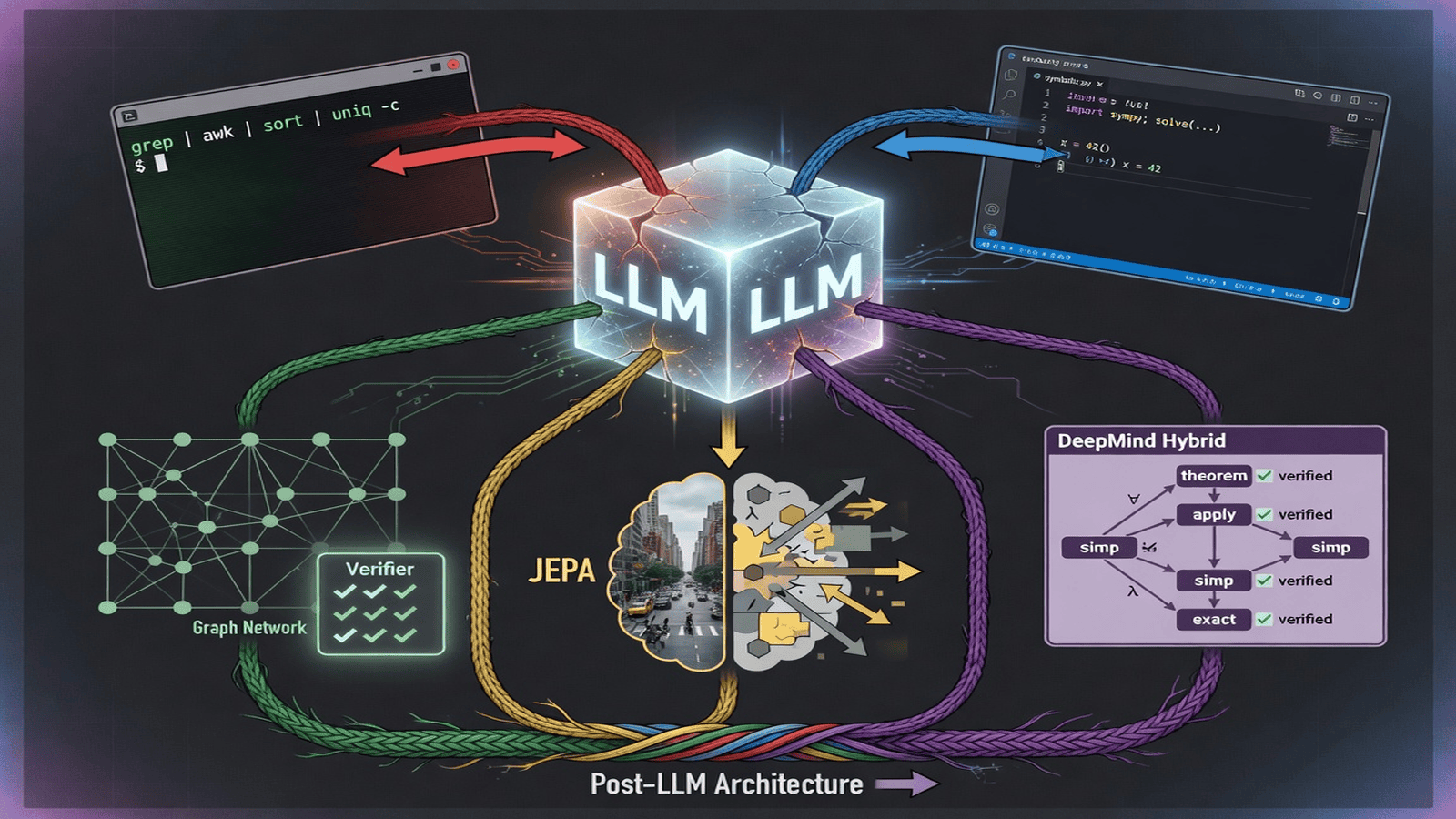
I. Aumentación — Parches que Funcionan
La respuesta más pragmática: mantener el modelo, darle herramientas. Esto ya está ocurriendo y es probablemente la dirección más productiva de la IA aplicada hoy.
El encadenamiento de pensamiento pide al modelo pensar paso a paso antes de responder. Mejora el desempeño en tareas multietapa porque externaliza estados intermedios en texto, dándole al modelo más espacio de trabajo. Pero no es razonamiento—es generación con forma de razonamiento. El modelo produce tokens que parecen cadenas de razonamiento porque sus datos de entrenamiento contenían cadenas de razonamiento. Nunca se compromete con un paso lógico. Genera el siguiente token que la distribución dice que pertenece allí.
La ejecución de código es cualitativamente diferente. Cuando un LLM genera Python y el intérprete lo ejecuta, el resultado está garantizado correcto para ese cálculo. El modelo no necesita conocer la respuesta; necesita generar código que la compute, y el intérprete impone corrección. Esto habilita cálculo matemático que el modelo no puede hacer mentalmente, manipulación de datos que de otro modo alucinaría, llamadas a APIs externas, generación de visualizaciones, y manipulación simbólica mediante sistemas de álgebra computacional.
La aumentación más subestimada: acceso a herramientas Unix en una caja de arena. Dale al LLM grep, awk, sed, sort, uniq, find, curl, jq—los modelos de lenguaje pequeños originales. Estas son herramientas verificables, reproducibles, eficientes que hacen una cosa bien. El trabajo del LLM no es conocer la respuesta sino generar la tubería shell que la produce. Las herramientas son determinísticas (misma entrada, misma salida), transparentes (cada resultado intermedio inspeccionar), económicas (un grep sobre 10 GB cuesta microsegundos), componibles (las tuberías son modulares y testables), y probadas en batalla durante décadas.
El patrón es idéntico a la generación de código: el LLM actúa como traductor entre lenguaje natural y shell. El usuario dice “encuentra los 10 tipos de error principales en los registros de hoy.” El LLM genera grep ... | awk ... | sort ... | head. El shell lo ejecuta. El LLM lee la salida y resume. El LLM nunca necesita saber qué son los errores. Necesita saber cómo pedirle a la computadora que los encuentre.
II. Arquitecturas Híbridas — Neural + Simbólica
En lugar de parchear una red neuronal pura con herramientas, las arquitecturas híbridas integran componentes simbólicos directamente. La red neuronal maneja percepción y reconocimiento de patrones; el componente simbólico maneja razonamiento, restricciones, y cómputo verificable.
La integración neuro-simbólica empareja una red neuronal que mapea entradas crudas (imágenes, texto, datos de sensores) a representaciones estructuradas (predicados lógicos, gráficos, entidades tipadas) con un razonador simbólico operando sobre esas representaciones para producir salidas garantizadas como válidas. La síntesis neural de programas tiene la red neuronal generar esbozos de programa; el motor simbólico rellena detalles y verifica corrección. La demostración de teoremas neural tiene una red neuronal seleccionar premisas y generar pasos de prueba; un verificador simbólico chequea cada paso. Las redes neurales de gráficos con solucionadores de restricciones aprenden a predecir restricciones y encontrar soluciones óptimas.
El beneficio: el componente neural proporciona la flexibilidad que los sistemas puramente simbólicos carecen—generaliza de ejemplos, maneja entradas ruidosas, aprende de datos. El componente simbólico proporciona la garantía que los sistemas puramente neurales carecen—prueba corrección, impone restricciones, produce cadenas de razonamiento auditables. El costo es dificultad de integración: sistemas neurales y simbólicos operan sobre representaciones fundamentalmente diferentes (vectores vs. símbolos, probabilidad vs. lógica, descenso de gradiente vs. búsqueda).
Las redes de gráficos de DeepMind abordan explícitamente la limitación de que las redes neurales estándar no tienen noción integrada de relaciones. Procesan conjuntos de características, no relaciones estructuradas entre entidades. Las redes de gráficos operan sobre gráficos donde nodos representan entidades, aristas representan relaciones, y la red aprende a propagar información a lo largo de aristas. Esto es simbólico en estructura (el gráfico es discreto, inspectable) mientras que neuronal en aprendizaje (actualizaciones de nodo y arista son funciones aprendidas). AlphaFold demuestra el plegamiento de proteínas como un gráfico de aminoácidos. La estructura se aprende pero es explícita—puedes observar el gráfico y ver qué el modelo piensa está relacionado.
La generación aumentada por recuperación (RAG) es el híbrido más simple: el modelo consulta una base de datos externa y condiciona su generación en información recuperada. Esto aborda anclaje—el modelo no confía en datos de entrenamiento memorizado sino en documentos recuperados, actuales, verificables. Variantes como Self-RAG, ReAct, y Toolformer entrelazan trazos de razonamiento con llamadas de herramientas. El insight es que un modelo con herramientas no es más inteligente; es capaz diferentemente. Descarga cómputo que no puede hacer confiablemente (aritmética exacta, recuperación de hechos, cálculo de fechas) a herramientas que sí pueden. El modelo se convierte en un orquestador, no un almacén de conocimiento.
III. Alternativas — Más Allá de la Predicción del Siguiente Token
Si la aumentación y la hibridación son parches, ¿qué hay sobre reemplazar el paradigma mismo?
JEPA (Arquitectura Predictiva de Encaje Conjunto) es la crítica directa de Yann LeCun del paradigma generativo subyacente a los LLM. Los LLM aprenden prediciendo tokens faltantes en una secuencia. JEPA aprende prediciendo representaciones de información faltante, no la información misma. Un codificador de contexto procesa entrada observada; un codificador de objetivo procesa entrada completa. Una red predictora toma la salida del codificador de contexto y predice la representación del codificador de objetivo de la parte oculta. La pérdida está en espacio de representación, no en espacio de entrada.
Al predecir representaciones en lugar de tokens crudos, JEPA es forzada a aprender características abstractas, de alto nivel del mundo—estructura subyacente, no estadísticas de superficie. No necesita generar cada píxel de una imagen o cada token de texto. Necesita generar una representación compacta capturando el significado de información faltante. Esto es más cercano a cómo los humanos aprendemos: no predicamos cada detalle sensorial del futuro; predicamos la esencia—la estructura de alto nivel que importa para la toma de decisiones.
JEPA ha sido demostrada en imágenes y video (aprendiendo dinámicas físicas sin supervisión explícita). Un JEPA basado en texto aún es una dirección de investigación abierta. La apuesta: si JEPA funciona a escala, podría producir modelos con comprensión genuina—representaciones comprimidas del mundo que capturan estructura causal, no solo correlaciones estadísticas. Esto aborda alucinación y anclaje desde las raíces, porque el modelo sería optimizado por significado, no por probabilidad de superficie.
Los modelos mundo son simulaciones aprendidas de dinámicas del ambiente. El modelo no predice el siguiente token o fotograma sino cómo el mundo evoluciona en respuesta a acciones. Ha y Schmidhuber demostraron un agente pequeño aprendiendo una representación comprimida de su ambiente, un modelo de dinámicas prediciendo representaciones futuras dadas acciones, y un controlador actuando en espacio de representación aprendida. El agente aprende a conducir en un sueño—enteramente de representaciones predichas, nunca viendo el ambiente real. Dreamer y DayDreamer extienden esto: aprendiendo modelos mundo de observaciones de píxeles, planeando imaginando trayectorias futuras en espacio latente, logrando desempeño competitivo en tareas Atari y control continuo.
Los modelos mundo están anclados por definición—aprenden de interacción con un ambiente, no de corpus de texto estático. Producen predicciones que pueden ser verificadas—actúas, observas, actualizas. El ciclo de retroalimentación es real. Aprenden estructura causal—el modelo debe aprender que acción A causa efecto B o falla en su tarea. El vacío: los modelos mundo funcionan en ambientes restringidos (juegos simulados, robótica simple). Escalado a complejidad de lenguaje es abierto. Pero el principio—aprender de interacción en lugar de texto—aborda la brecha fundamental de anclaje que los LLM no pueden cruzar.
El enfoque híbrido de DeepMind separa generación de verificación. AlphaGeometry resuelve geometría a nivel olímpico haciendo que un modelo de lenguaje neuronal genere construcciones candidatas y un motor de deducción simbólica verifique si conducen a una prueba. AlphaProof usa un modelo neuronal para generar pasos de prueba en Lean, con el verificador imponiendo corrección. La búsqueda de pruebas neurales en Lean aprende del feedback del verificador qué estrategias funcionan.
Esto funciona porque separa generación de verificación. La red neuronal genera candidatos libremente—creativos, sorprendentes, equivocados. El motor simbólico filtra rigurosamente—solo candidatos satisfaciendo restricciones formales sobreviven. Esto es opuesto a un LLM, que genera y verifica en un paso; predicción del siguiente token implícitamente reclama “este token es correcto.”
El camino adelante no es predictores mejor de siguiente token sino arquitecturas donde:
- Un componente generativo explora el espacio de posibilidad (neuronal, probabilístico, alta varianza)
- Un componente verificador filtra resultados (simbólico, determinístico, baja varianza)
- Feedback entre ellos conduce el aprendizaje
IV. El Paisaje
Cuanto más anclaje, determinismo, y explicabilidad necesites, más debes moverte lejos de predicción pura del siguiente token hacia arquitecturas con verificación explícita, interacción con mundo, o componentes simbólicos. LLM puros ofrecen ninguno de estos pero están listos para producción a escala. Aumentación con ejecución de código o herramientas Unix te compra anclaje medio y determinismo a costo alto. Redes de gráficos, integración neuro-simbólica, y modelos mundo intercambian costo y madurez por garantías más altas. El enfoque híbrido de DeepMind (estilo AlphaGeometry) te compra el anclaje y determinismo más altos pero requiere formalización de dominio costosa.
V. La Síntesis
Una arquitectura post-LLM podría combinar:
Un módulo de percepción (neuronal, entrenado) mapeando entradas crudas a representaciones estructuradas—entidades, relaciones, propiedades.
Un modelo mundo (neuronal, entrenado) simulando evolución de representación sobre tiempo y en respuesta a acciones, aprendido de interacción.
Un razonador simbólico (determinístico, sin entrenar) operando sobre representaciones estructuradas para deducción, satisfacción de restricciones, verificación—proporcionando garantías.
Una interfaz de herramientas (conectable) conectando a bases de datos, motores de búsqueda, intérpretes de código, herramientas Unix, APIs—proporcionando acceso a cómputo externo verificable.
Un orquestador (LLM pequeño o controlador aprendido) coordinando los otros—decidiendo cuándo percibir, simular, razonar, actuar.
El LLM, en esta arquitectura, se reduce a un componente—el orquestador—en lugar de todo el sistema. Su trabajo no es conocer todo sino encaminar solicitudes al componente correcto y sintetizar resultados en coherencia.
Esto ya está ocurriendo en sistemas de investigación. La pregunta es qué tan rápido escala y si los desafíos de integración pueden resolverse a niveles de producción.
Lecturas recomendadas
- Jason Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” (2022)
- Schick et al., “Toolformer: Language Models Can Teach Themselves to Use Tools” (2023)
- Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models” (2023)
- Battaglia et al., “Relational Inductive Biases, Deep Learning, and Graph Networks” (2018)
- Yann LeCun, “A Path Towards Autonomous Machine Intelligence” (2022)
- Ha and Schmidhuber, “World Models” (2018)
- Hafner et al., “DreamerV3” (2023)
- Trinh et al., “AlphaGeometry: An Olympiad-Level AI System for Geometry” (2024)
- DeepMind, “AlphaProof” (2024)
- Rich Sutton, “The Bitter Lesson” (2019)